データに意味づけするためには、分類が必要です。このデータは名前なのか、年齢なのか、金額なのかと考えて、仕分けしなければなりません。これが体系化です。
体系化されたデータを共有するために一元管理する仕組みがデータベースです。一元管理とは、体系化されたデータを一か所に蓄積し、保全することです。
■データベースの必要性
データ量が増え、たくさんの人達と共有化することになると、データを一元管理しなければならなくなります。
体系化されたデータは、ファイルに保存されます。データが少量であるうちは、ファイルだけで事足ります。
しかし、しだいにデータの種類とデータ量が増えてくると、ファイルでは、正確に必要なデータを見つけ出すことが難しくなってきます。
その結果、もっと簡単にデータを見つけ出せるようにするための「データベース化」が実施されることになります。そこで、登場するのがデータベース・ソフトウェアです。
データベース化には、データベース・ソフトウェアに入れるために、現状の散乱したデータを寄せ集め、ばらばらの形式のデータを変換する作業が必要となります。この作業は、自動化することが難しく、手間がかかります。
しかし、それでも、いったんデータベース化できれば、蓄積されたデータは、形式知として、資産化することができます。
■データベースの機能
データベースに備わる機能は、以下の通りです。
1)データ定義
データの型を定義する機能。一般的に、文字列型、整数型、実数型、日時型などが定義できます。
2)検索
データを検索する機能。AND条件、OR条件を組み合わせて、条件設定ができます。
3)追加・更新・削除
データを新規に追加、更新、削除する機能。リアルタイム、あるいは、バッチによりオフラインで登録・更新・削除できます。
4)データ保全
データベースから蓄積されたデータを取り出し、ハードディスクやDVDなどの外部装置に保管するバックアップ機能と、逆に、データベースのクラッシュが発生したときに、外部装置からデータベースに戻すリストア機能。全体バックアップ、差分バックアップができます。
■データベースの種類
データベースには、管理するデータに適した以下のように種類があります。
1)リレーショナルデータベース(RDB)
ある情報の集合をテーブルとして定義し、管理します。テーブルは、列(カラム)と行(レコード)の表形式で定義されます。
カラムには、情報の特徴を示すデータが複数、定義され、レコードには、全カラムで定義された一組のデータ群を持つ情報の実体が登録されることになります。
仕事でよく使われれるExcelのように、表でデータを管理することで、ほとんどのデータの整理はできてしまいます。通常、データベースと言えば、RDBを指します。
2)全文検索データベース
新聞や雑誌の記事、書籍などは、大量のテキストデータで構成されます。この大量のテキストデータを検索することを「全文検索」と言います。全文検索を高速に実施するには、大量のテキストデータを処理するためのアルゴリズムが必要となります。このアルゴリズムを持ち、高速全文検索に特化したデータベースのことです。
3)ネットワークデータベース
データとデータに接続するように、リンク関係を生成ことで、データ間の関連を管理します。蜘蛛の巣のような関連をつくることができます。
たとえば、twitterのフォロワーのネットワークであるとか、人脈のネットワークのようなデータを管理するのに適しています。
4)「NoSQL」データベース
上記のデータベース以外の新しいデータベースです。リレーショナルデータベースのSQL言語処理や複雑な管理構造を持たず、より単純化し、拡張性に優れた構造とすることによって、特定用途でデータを扱いやすくしています。
例えば、キーワードと対応する値の構造だけを管理できるもの、JSON形式のデータを管理できるものなどがあります。
■RDBの機能
最もよく使われるデータベースのRDBについて、基本機能を述べていきます。
1)スキーマ定義
スキーマとは、データの集合を管理するための構造のことです。スキーマ定義は、以下の2つの定義することです。
・データベース
データを入れる箱の定義。すべてのテーブルは、この中に定義されます。データベースにアクセスできるユーザの管理もデータベース単位で行われます。
RDBでは、複数のデータベースを作成できます。データを使う目的によって、データベースを作成します。
・テーブル
データベースの中では、「情報」毎に表形式でデータ構造を定義します。これを、テーブルと言います。テーブルの定義とは、カラムの名前と属性を定義することです。 全カラムのデータを持つ一組のデータ群を、レコードといいます。

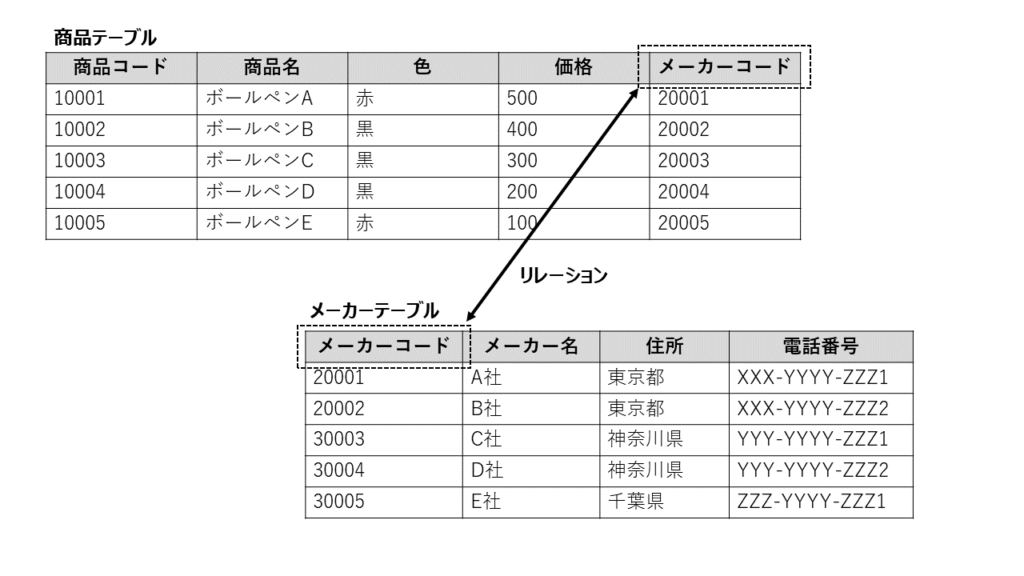
2)リレーション
「情報」と「情報」の間には、関係(リレーション)が形成される場合があります。たとえば、商品という情報には、”メーカー”というデータが含まれ、メーカーという情報は、企業名、住所、電話番号、メールアドレスなどのデータをもっています。
テーブルでは、カラムに、他のテーブルの識別子(キー)となるデータを定義することでリレーションを表現します。テーブルの中のデータに他のテーブルのキーがあれば、テーブル間の”つながり”があることを意味します。
リレーションは、情報を最小単位に分けることでつくられます。これを「正規化」と呼びます。
正規化とは、共通化です。データベース内で管理するすべての情報において、各情報の構成するデータの重複をなくすため、共通化すべきデータを洗い出すことです。洗い出したデータを情報としてまとめ、テーブルを定義します。
その結果、テーブル間のリレーションをつくることができます。
正規化によるリレーションをつくることのメリットは、重複したデータが引き起こすデータ不整合の防止です。たとえば、商品のテーブルの中にメーカの会社名やメールアドレスのデータを持つようにしたとします。もし、会社名やメールアドレスが変わったら、同じメーカの全商品のレコードを変更する必要があります。もし、変更漏れがあると、同じメーカのはずなのに、違う会社名やメールアドレスとなってしまいます。
正規化し、メーカのテーブルで、会社名やメールアドレスを定義し、商品のテーブルとメーカーの識別子でリレーションを作成しておけば、メーカのテーブルの該当レコードの会社名やメールアドレスを変更するだけで済み、不整合の発生を無くすことができます。
一方、正規化のデメリットとしては、検索の処理速度です。たとえば、検索でヒットした商品のメーカに関する情報を表示する場合、商品のテーブルだけでなく、メーカのテーブルも検索する必要があります。
テーブルのレコードの件数が膨大でなければ、問題とはなりませんが、レコード件数が多い場合、問題となります。そのため、正規化の逆に、「非正規化」をし、あえてデータの重複をさせることがあります。
データベースで管理するデータには、以下の2種類があり、両方ともテーブルで管理されます。データベースの役割は、トランザクションデータを蓄積し、利用できるようにすることです。マスタデータは、トランザクションを蓄積し、利用するために、必要な補助データです。
①マスタデータ
共通のデータであり、辞書のような役割をします。たとえば、商品マスタ、顧客データ、企業データなど、原則、変化することのない固定のデータです。。
データベースを使ったソフトウェアやシステムでは、マスタデータがないと運用ができません。マスタデータは、あらかじめ準備しておく必要があります。そういう意味では、マスタデータとは初期データと同じ意味を持ちます。
マスタデータは、データ量は一定で、その構造もあらかじめ把握することができます。そのため、テーブル間のリレーションを決めることができ、整合性を保つために正規化をすることができます。
②トランザクションデータ
内容が多様で、ランダムに発生するデータです。たとえば、商品を購入するときの取引データ、計測装置からの計測データなど、随時で発生するデータです。データベースに蓄積すべきデータは、このような随時生成されるトランザクションデータです。
トランザクションデータを使って、分析や予測を行い、業務を効率化することがでいます。
トランザクションデータは、時間がたつにつれ蓄積されていきます。データ量が多く、処理時間を確保する必要があるトランザクションデータは非正規化をします。
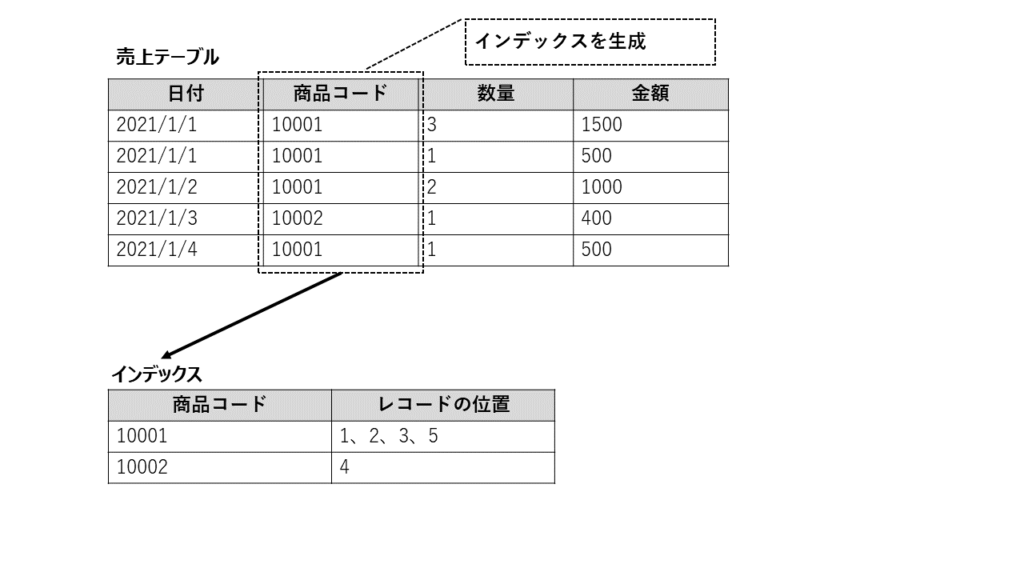
3)インデックス
インデックスとは、検索を高速にするため、テーブルの一部のカラムのデータだけを抽出したものです。インデックスは、テーブルとは別に作られます。
インデックスの構造は、同じカラムのデータを持つテーブルの複数レコードの位置を保持しています。たとえば、アドレス帳テーブルの名前のカラムのデータが「田中」だったら、「田中」の名前のレコードの位置が1、5、10というようにインデックスで管理されます。
その結果、インデックス化されたカラムのデータを指定した検索をすると、インデックスが先に検索されることで、すぐに特定数のレコードの位置がわかり、テーブルを頭から検索するよりもずっと高速化することができます。
デメリットは、テーブルへレコードを登録、更新、削除する際、インデックスにも同時に登録、更新、削除されますので、処理時間が増加することです。
トレードオフはありますが、データベースの利用目的は検索にありますので、インデックスを使うことでデータベースの性能を上げることができます。
4)SQL言語
RDBには、プログラミング言語のようなデータベースを定義・操作するための特別な言語があります。それがSQL言語です。
これによって、RDBであれば、たとえ製品が違っても、同じ方法でアクセスすることができます。
SQL言語は、プログラミング言語と同じように文法があります。ただし、プログラミング言語のように難しくはなく、単純です。
単純に言うと、文法としては、以下の順で記載します。
[操作] [テーブル名] [条件]
操作には、検索(SELECT)、登録(INSERT)、更新(UPDATE)、削除(DELETE)があります。
条件は、カラムのデータにする一致(中間、前方、後方)、不一致、範囲、以上、以下、より大きい、より小さいなどを、論理積(AND)、論理和(OR)による組み合わせを記載します。
また、データベースを使ったプログラミングとは、プログラミング言語によって、SQL文を組み立てて、各種テーブルにアクセスすることです。

5)トランザクション
複数のテーブルに対して、一連の流れで、複数のレコードを登録・更新・削除をする場合があります。たとえば、商品を売り上げた場合、売上テーブルにレコードを追加し、在庫テーブルの商品レコードを更新するようなときです。
この一連の処理を、グルーピングして処理するのがトランザクションです。
トランザクションを使った処理は、以下のような手順で行われます。
①トランザクションの開始
②SQL言語による複数テーブルへの登録、更新、削除(仮の処理)
③コミットによる実処理
②の処理は、仮の処理として、実際にはテーブルへは処理されません。③のコミットを実行されたときに、テーブルへ反映されます。
一連の処理において、途中の結果によっては、その前のレコードの登録・更新・削除を取り消す必要があります。コミットを実行するかわりに、ロールバックを実行します。トランザクションを使うことで、それまでのテーブルの処理を簡単に取り消すことできます。


</span>")


</span>")